Getting Started with Digital Asset Management (DAM): Metadata Part 1


This is Part 1 of a two-part series on Metadata and how it relates to Digital Asset Management. This post covers the basics of metadata, including history, definitions, and how metadata gets created. In Part 2 of this series, Getting Started with Digital Asset Management (DAM): Metadata Part 2, you’ll learn about how to manage metadata for your digital assets.
Metadata. You’ve probably heard this term while researching Digital Asset Management Systems as it is an important part of any system’s functionality. But whether you’ve heard it or not, metadata is all over the place, helping you find what you need all over the internet, in libraries, databases, and archives.
Metadata, simply put, is data about data. It’s information that describes another piece of information, such as a book, photograph, or webpage, and makes it easier to find. It helps researchers in libraries find relevant information, useful resources, or local information. In terms of digital marketing and digital asset management - metadata allows people to organize and display content, allowing for easier reuse. Metadata makes information findable not just by humans, but by machines as well. In many cases, the metadata is as important as the asset itself. Without it, files could be lost forever. And without metadata describing things like usage rights and creator information, an asset can lose its value over time. For these reasons, it’s important to think carefully about your metadata and how it works with your Digital Asset Management Platform.
A Brief History of Metadata

First Use of Metadata - Great Library of Alexandria
Metadata has been around for a long time in one form or another. The first known use of metadata dates back to 280 BC, in the Great Library of Alexandria. Led by Greek grammarian Zenodutus, the library staff attached small hanging tags to each scroll describing each works author, title and subject so that researchers did not have to unroll each scroll to see what it contained. The librarians were then able to easily put the scrolls back in the section where they belonged after each use.
In the early 1800s, photographers would scratch the date, location, and subject description onto daguerreotype (the first photography format) creating one of the first “modern” forms of metadata. In 1876 the Dewey Decimal System was invented to classify books by subject so they could be easily found. Before that, books were generally stored based on their size and date they were acquired. Not very helpful when you were looking for something specific! And many of us still remember card catalogs, which libraries used for many years to organize data about books and help you locate them - another early form of metadata.
MARC, or Machine Readable Cataloging, was invented at the Library of Congress by American computer scientist Henriette Avram in the 1960s to create records that could be read by computers and shared among libraries. MARC is still used today in its 21st iteration and is used to catalog over 400 million records all over the world. If you’ve ever taken a book out of your local library, chances are you’ve used a MARC record metadata entry.
It was only once electronic records first became prevalent that folks started actually using the term “metadata” itself. In 1979, The International Press Telecommunications Council (IPTC) came up with a standard around metadata that could be used with images, and in 1994 Adobe developed a method to embed this information into the photo file. IPTC information is still in use today, and many digital asset management systems import and show this data if it is embedded in an asset.
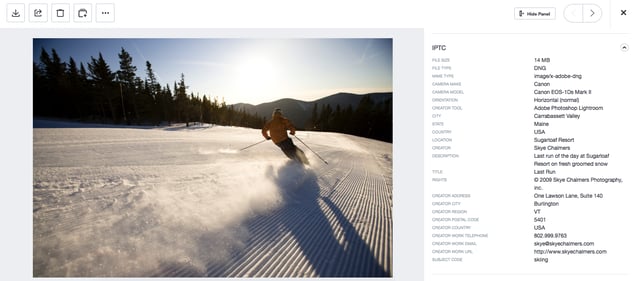
IPTC Photo Image Metadata Example
As our society has become more and more digital, the amount of metadata and its uses has increased exponentially. With the advent of search engines such as Google, metadata is essential to provide information about websites so that the right results can be found and retrieved. From a marketing standpoint, refining and utilizing proper metadata has become a crucial part of the job, as relevant metadata will help a product or service show up in an internet search with thousands or millions of results. And having proper metadata in your digital asset management system will let you find and reuse the many assets that you have. And to think it all started in a library in ancient Alexandria!
Types of Metadata
Metadata is generally grouped into three main categories. Descriptive, Structural, and Administrative.
Descriptive metadata describes an asset for purposes of discovery and identification. It might include title, author, subject, date created, marketing description, and keywords to further describe it. This is the most common type of metadata that you will see in digital asset management.
Structural Metadata describes how something is put together such as pages in a chapter or chapters in a book. In a digital environment, files are frequently stored separately and this information shows how they are related. This kind of metadata is used frequently in publishing.
Administrative Metadata provides information to help manage a resource, such as a file type, size, when and how it was created, and who can manage it. Within Administrative metadata, there are two subcategories. Rights Management Metadata deals with intellectual property and reuse rights, and is frequently handled by a legal team. Preservation Metadata contains information on how to archive and preserve a resource and applies to both physical and digital assets.
Metadata Schemas
Metadata is usually arranged according to what is called a “schema.” Metadata schemas organize the overall structure of the metadata. They outline how the metadata is structured and create a standard set of fields. These fields are officially called “elements” and they might include title, subject, format, and creator. Metadata schemas also include best practices about how to fill in these elements and this is called “semantics.”
There are many metadata schemas in the world, some more broad and some industry-specific, but there is generally no one size fits all schema. One of the most well-known metadata schemas is the Dublin Core, which was can trace its beginnings to 1995 shortly after the world wide web was developed. Dublin Core can be adapted to many situations and different contexts such as libraries, web pages, and other kinds of databases such as a digital asset management system. Another popular standard is MARC which was mentioned above and is used by the Library of Congress.
There are also some very specific metadata schemas that are only applicable in certain fields. MEI, the Music Encoding Initiative, is used in the representation and exchange of music information. VSO, or Virtual Solar Observatory, is used to describe solar data sets in Astronomy. DwC, or Darwin Core, is used to describe nature as documented by observations, specimens, samples, and related information. Perhaps not as useful for your digital asset management, but fascinating in its scope.
Controlled Vocabulary
Working alongside the schema is the “Controlled Vocabulary.” This is the controlled content that you can use to fill in your elements field. A controlled vocabulary is established ahead of time and limits what information users can enter. This assures that users aren’t entering irrelevant information or information that is spelled or formatted incorrectly. Controlled vocabularies might include brand names, departments, product lines, sizes, flavors, and much more.
As with schemas, there are many examples of established controlled vocabularies, and they can become quite elaborate. There are thesauruses such as The Thesaurus for Graphic Materials, a tool for indexing visual materials run by the Library of Congress and The Art and Architecture Thesaurus, developed by The Getty Research Institute for concepts related to art, architecture, and other cultural heritage. If you want to look at some more common forms of controlled vocabularies, go take a look through the navigation on sites like Amazon and IMBD. It’s easy to take for granted, but it’s a guarantee that librarians at these two organizations spent lots of time creating the controlled vocabularies used on these websites. And it would be hard to find anything if they had not!
As you can see, Digital Asset Management and Metadata go hand-in-hand. Looking to understand the value that Digital Asset Management can create in your organization? Read our guide: The Value of Digital Asset Management.
How is metadata created?
People - The main way that metadata is created is by people! Metadata created by humans is the easiest kind of data for other humans to read and therefore the most useful in helping users find what they need. Humans can recognize elements that computers have a difficult time with, such as quickly assessing what’s going on in a photo, or the ability to summarize what’s in a spreadsheet. Because of this, giving people working in and managing your digital asset management metadata guidelines around what to enter can improve quality and smooth the process.
Computers - Some metadata is automatically created by computers or machines. In the case of a Digital Asset Management System, information such as file type, creation date, uploader, and file size may all be automatically created. In some cases, computer-created metadata can be difficult to read by humans and may speak directly to another computer.
Extraction - In some instances, metadata is extracted from other systems. For example, information may be extracted from a Human Resources database that best identifies people. Or in the case of Digital Asset Management Metadata, your Digital Asset Management System might speak to a Product Information system to extract information about products.
Artificial Intelligence - Some programs are starting to use Artificial Intelligence to create metadata that describes an image or document. While great strides have been made in this area, it is still quite inaccurate and must always be edited by humans.
In Part 2 of this series on DAM Metadata we will show you how to turn this basic metadata understanding into an action plan for creating the metadata schema and controlled vocabulary for your team.
For more in our Getting Started with Digital Asset Management Series, check out these helpful resources:
Getting Started with Digital Asset Management (DAM): Managing User Access with Permissions
Getting Started with Digital Asset Management (DAM) Software: Mapping Your Organization’s Content
Getting Started with a Digital Asset Management (DAM) Platform: Best Practices for File Types
Getting Started with Digital Asset Management (DAM) Software: Understanding Your Team Needs
Getting Started with Digital Asset Management (DAM): Metadata Part 2
Getting Started with Digital Asset Management (DAM) Software: File Naming Best Practices



